
Perspective
Autonomous network operations Network predictions in real time

The network operations center (NOC) represents the nerve center of a telecommunications carrier, where large teams ponder over innumerable parameters of information generated from network elements, OSS, and BSS tools, including active and passive sensors monitoring the network, in order to take decisions on running it better and resolving problems, which inevitably erupt. Telecommunications service providers (TSPs) have long recognized the value offered by this data and have set up large teams of data scientists, network engineers, and technicians to analyze, report, and react on this data so as to minimize damage caused by harmful events or prevent them, as also to assess trends and patterns meant for predicting its behavior.

The increasing number of parameters being monitored, and their rising frequency, is an indication of their vitality to a TSP’s operations, but often also cripple NOC teams from being able to unearth reliable and holistic insights, and are invariably forced to remain focused on only a few metrics of interest. NOC engineers rarely get an opportunity to look at the data available in different domains and correlate them to assess their real impact, whether to predict a customer-impacting crisis or a business opportunity. There have been instances when even very clear indications of impending crisis were missed at the opportune time for want of cross-domain correlation of data available with different teams in the NOC. The situation is analogous to driving on a race track with gaping blind spots. There is simply too much data to analyze and not enough time, resources, and talent to act upon them.
Figure 1: The quantum of data collected far exceeds that which is analyzed in conventional network operations centers.

Recent advances in AI/ML promise to radically change the way NOCs work as the focus will turn from real-time network monitoring to real-time network prediction. New tools promise to collect, analyze and act upon data inputs on a giant scale autonomously – with human interaction required to supervise and score on the action taken by these machines.
Anodot is amongst the pioneers in providing a holistic platform, which autonomously assimilates data available from network elements or tools, and applies AI/ML techniques to not only understand their significance, but also to correlate them with parameters from across different domains to predict events in real time. The tool looks at all-time-sequenced data, regardless of its source, and learns the normal behavior of those parameters. A sinusoidal pattern of behavior associated with usage and traffic is typical in telecommunication networks. But any anomaly in such normal behavior is sensed and reported, especially if it is seen to correlate to multiple anomalies in different parameters at the same time. The platform learns and understands the potency of each anomaly, and is ready to create meaningful alarms within days of commissioning. As with other AI/ML tools, the platform keeps improving its efficacy and within a few weeks, begins to predict events even before they impact business. Figure 2 shows an example of normal downlink traffic volume in GB for a base station, and the deviation from the normal (anomaly) detected at a specific time.
Figure 2: Machines learn the normal behavior of time-varying data and detect anomalies.
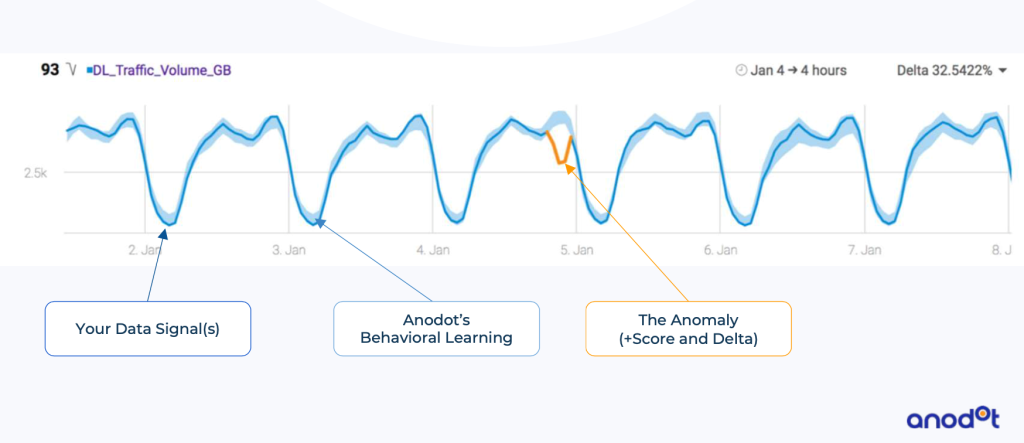
Each such anomaly is given a score, initially with user feedback, and then automatically as the tool begins to understand the network. The platform raises an alarm with a severity based on the score, the delta (deviation from the normal), and the count of parameters in anomalies. For example, a 20-percent drop in DL traffic volume across hundreds of base stations in an area points to a larger problem, probably with an aggregation router than if detected only in a single base station.
Figure 3: Correlation of traffic volumes at different terminals w.r.t. SNR in serving network elements
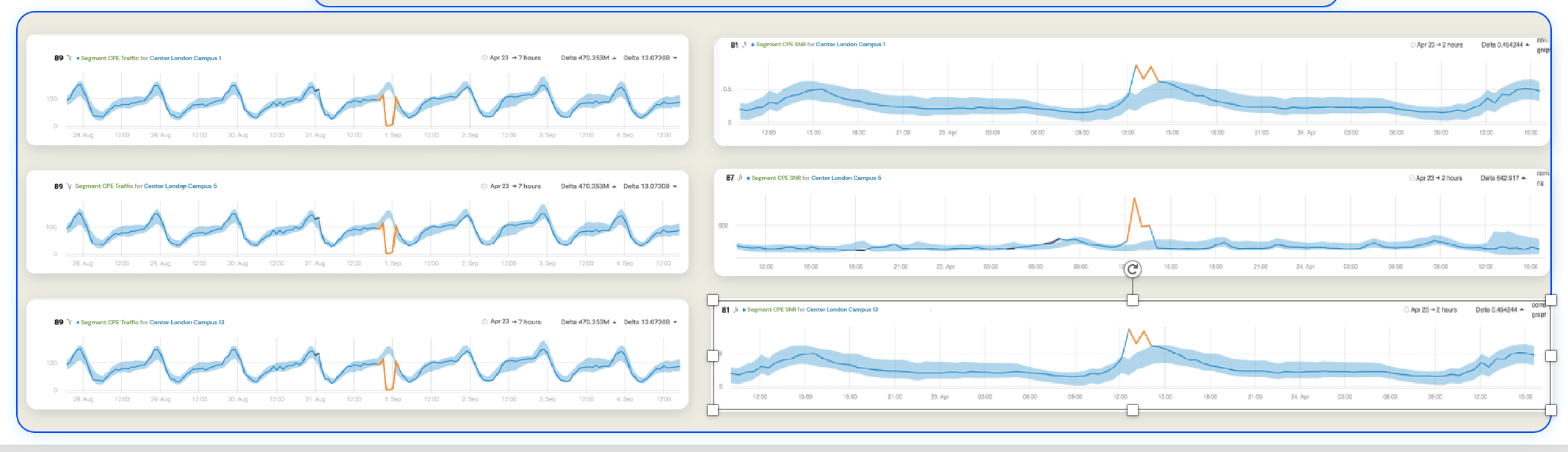
Figure 3 shows how anomalies from different data lakes (whether from network elements, EMS, NMS, tools, etc.) are correlated based on time synchronization. Such anomalies may be spread across diverse applications, e.g., data and voice/VoLTE correlation across RAN, backhaul, and core; network slicing and Vo5G; enterprise data service correlation for MPLS and Ethernet services, latency across FTTH, microwave and MPLS backhaul, and so on. Any parameter logged with time can be fed to the platform and correlated to any other. Platforms like Anodot have the capacity to ingest millions of parameters and dimensions so as to be able to support the scale required in large telcos, and are already being used by a few global TSPs, such as AT&T, Optus, and T-Mobile.
Artificial intelligence opens the door to ingest new metrics and make meaningful decisions based on these. We may shortly expect autonomous network monitoring and analysis a standard utility in all TSPs, providing for more responsive and better-managed telecommunications networks.













You must be logged in to post a comment Login